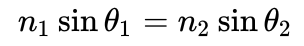LabriggerTips, tricks, hardware, and software for biomedical research2026-03-27T21:33:03Zhttp://labrigger.com/blog/feed/atom/WordPressL.<![CDATA[Consensus reality is a public good]]>https://labrigger.com/blog/?p=56962026-03-27T21:33:03Z2026-03-27T21:33:02Z
This comment by Ryan Cooper came to me from Mark Histed. It has stuck with me, and Mark has repeated the idea a few times. For years now, I’ve been annoyed at...
This comment by Ryan Cooper came to me from Mark Histed. It has stuck with me, and Mark has repeated the idea a few times. For years now, I’ve been annoyed at how hard it is to find good news sources. Conventional media can be compromised by multiple sources (gaining/retaining advertisers, billionaire owners), as can publicly supported media (government grants, donors), and social media is a thicket of grifters, echo chambers, and bots. Thus, the news that is easiest to find is often low quality.
But maybe I shouldn’t be so annoyed. Maybe I just needed to learn a bit more about other models out there. Like Mr. Rogers learned from his mother: “Look for the helpers.” Here are some examples. Maybe none of them are perfect, maybe you know better sources (please do share), but it’s wonderful that people are working on this public good. Here are some items:
The McKnight Foundation has funded efforts in this area. I’m fond of them because they are based not far from where I grew up, and they funded some early work in my own lab. Excellent people. Excellent organization.
The American Journalism Project is one of the efforts McKnight has helped to fund. They focus on helping local news sources develop.
So, the model of non-profit news can work. I admire PBS, NPR, and related organizations as well. They are filled with good people doing good work.
I’m doing this post for two reasons. The first reason is above: highlighting examples of successful non-profit news organizations covering politics and current events in a way that can help cultivate a consensus reality.
The second reason is to simply core dump some ideas of how to do more of this. And do it big. Here goes:
Completely decouple funding from operations. Start with a big endowment, and only operate on surplus. Generally that’s about 4% of the endowment annually. Accept donations, but 100% of donations have to go to the endowment. This way, the operations are never dependent on donations or any source of new funds. The fiduciary board must release the 4% annually and has zero power to veto specific stories or fire editors. Spending growth only grows as the endowment grows. This alone is a huge piece of the puzzle. But it’s not the whole package. Governance can still be corrupted. So how do we address that? Here are some ideas:
Distributed governance across multiple classes of stakeholders who nominate and elect leadership: (i) Internal, like staff reporters and editors– they care about the day-to-day operations and professional standards; (ii) Academics, like journalism and history profs– they care about getting it right long-term; (iii) Audience, like a random lottery of long-time subscribers who get to vote for leadership positions– they care about the product and how they can consume it; (iv) Librarians, they care about value, fact-checking, and archiving.
Regular turnover with ethics guardrails to ensure fresh, constructive leadership. Five-year, non-renewable terms for editors and other leaders. Top personnel cannot join a political campaign or a lobbying firm for three years after leaving, funded by a “severance tail” from the endowment to ensure they aren’t auditioning for their next job while in the editor’s chair.
Open source reporting processes to ensure that every story includes a public appendix of all raw transcripts, data sets, and conflict-of-interest disclosures for the writer. Sources can remain anonymous, of course, and editors can provide additional confidentiality as warranted.
Public Ombudsman who is a paid, high-profile, independent critic hired for a non-renewable term whose only job is to publicly eviscerate the organization’s own biases and errors every week.
None of these items are a silver bullet, and even in combination it cannot account for every corrupting influence. But it’s a start. And it’s not a particularly exotic start either– there is precedence for much of this. So whenever a billionaire buys a newspaper or media outlet, if they aren’t doing a lot of this, then their intention should be suspect.
I’ve written before about how a billionaire could do a big donation and instantly manifest a top tier research university. It would actually take less to instantly manifest a top tier news foundation focused on current events and politics to create a public good. Top-tier media organizations like the AP or the Guardian spend about $350-500 million per year. $10 billion would do it. There are hundreds of people in the world with that kind of money. And honestly, even 1/10 of that ($1 billion; thousands of people in the world have that kind of money) would do a lot and the foundation could build from there. That $40 million per year to start would already be more than the Intercept, the Texas Tribune, ProPublica, CalMatters, or many other impactful news organizations spend per year.
]]>0L.<![CDATA[Irrational medicine and the public’s minds]]>https://labrigger.com/blog/?p=56902026-03-21T19:08:28Z2026-03-21T19:08:28Z
“by opening the door to irrational medicine alongside evidence-based medicine, we are poisoning the minds of the public” – Baum and Ernst 2009 Source
“by opening the door to irrational medicine alongside evidence-based medicine, we are poisoning the minds of the public” – Baum and Ernst 2009 Source
Oliver Wendell Holmes Sr. wrote Homeopathy and Its Kindred Delusions in 1842. Over 180 years later, we’re still fighting, and the “lifeless delusions” are not so different. Anti-vax nonsense, COVID conspiracies, anti-pasteurization, and so on.
Breast cancer researcher Michael Baum is one of the standard bearers of this fight. He and Ernst warned “if we don’t put a brake on the increasing self-confidence of the homeopathic establishment, they will cease to limit their attention to self-limiting or nonspecific maladies” and similar caution is called for today.
Speak up. Call it out. Demand evidence and rigor, even in casual conversation. It’s our job. It’s our role.
After more than 200 years, we are still waiting for homeopathy “heretics” to be proved right, during which time the advances in our understanding of disease, progress in therapeutics and surgery, and prolongation of the length and quality of life by so-called allopaths have been breathtaking. The true skeptic therefore takes pride in closed mindedness when presented with absurd assertions that contravene the laws of thermodynamics or deny progress in all branches of physics, chemistry, physiology, and medicine. – Baum and Ernst 2009 Source
]]>0L.<![CDATA[Brodmann was right. Structure and function inform each other.]]>https://labrigger.com/blog/?p=56742026-01-23T19:44:34Z2026-01-23T18:40:14ZI saw this post, with this quote: “High-resolution activity maps of PFC did NOT align with cytoarchitecturally defined subregions.” Is this a profound, provocative finding that provides strong evidence for the irrelevance of cytoarchitecture?
...
]]>I saw this post, with this quote: “High-resolution activity maps of PFC did NOT align with cytoarchitecturally defined subregions.” Is this a profound, provocative finding that provides strong evidence for the irrelevance of cytoarchitecture?
I’m a big fan of high quality neuroanatomy. Korbinian Brodmann’s work gave us a framework and a set of landmarks for cortical organization. Careful neuroanatomists have elaborated upon that, making corrections along the way, and provided important details for understanding brain function, all underpinned with the understanding that structure and function inform each other. The best neuroanatomists reveal order in the brain, where it previously looked like spaghetti wiring.
His work is tightly linked with function. Measuring visual responses in vivo, making precision tracer injections, studying synaptic properties in vitro, and detailed analysis.
So when a paper claims that activity maps are not aligned with cytoarchitecture, I wonder what they actually did and what they found. Are they upsetting a central premise? Or are they making a more specific observation?
In the paper that kicked off the thread, the authors used a series of Neuropixels recordings in headfixed behaving mice, and analyzed the spontaneous spiking activity and task-related activity. They assigned units recorded to specific areas based the dye-labeled electrode tracks. Specifically, they estimated where they were on a common reference atlas using software. So they didn’t actually do cytoarchitectural analysis in the study to delineate areas. Other people in the thread cited somepapers looking at the question which did nice cytoarchitectural work in individual animals. But that wasn’t done here.
I think the atlas approach is useful, but when trying to make specific claims about cytoarchitecture, especially precise boundaries between adjacent areas, the lack of precision can be a problem. Brains vary in size and shape. The paper on the software they used actually discussed this, quite well in fact, so I’ll just paste it here:
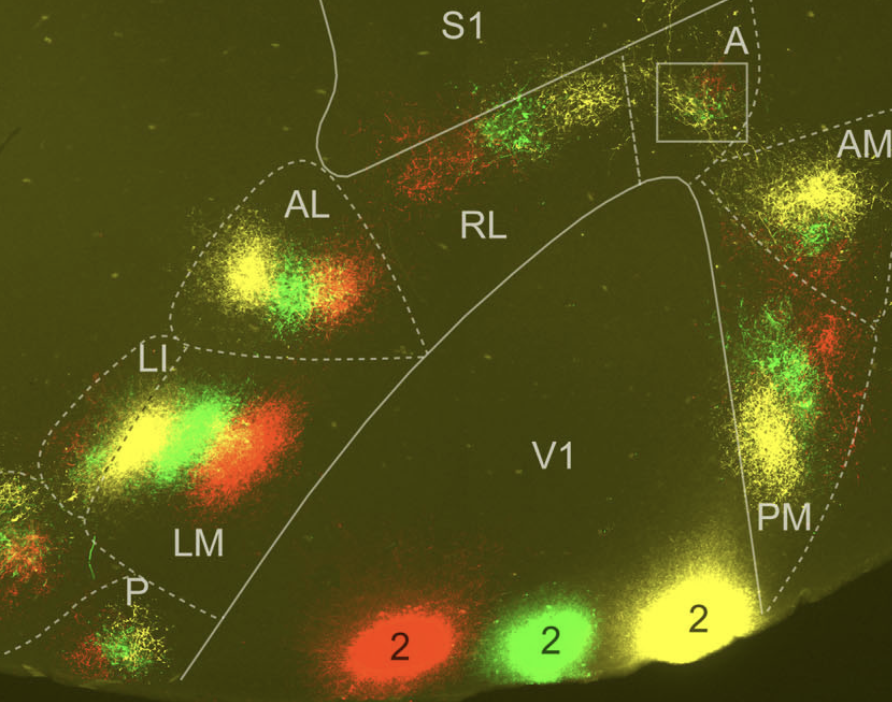
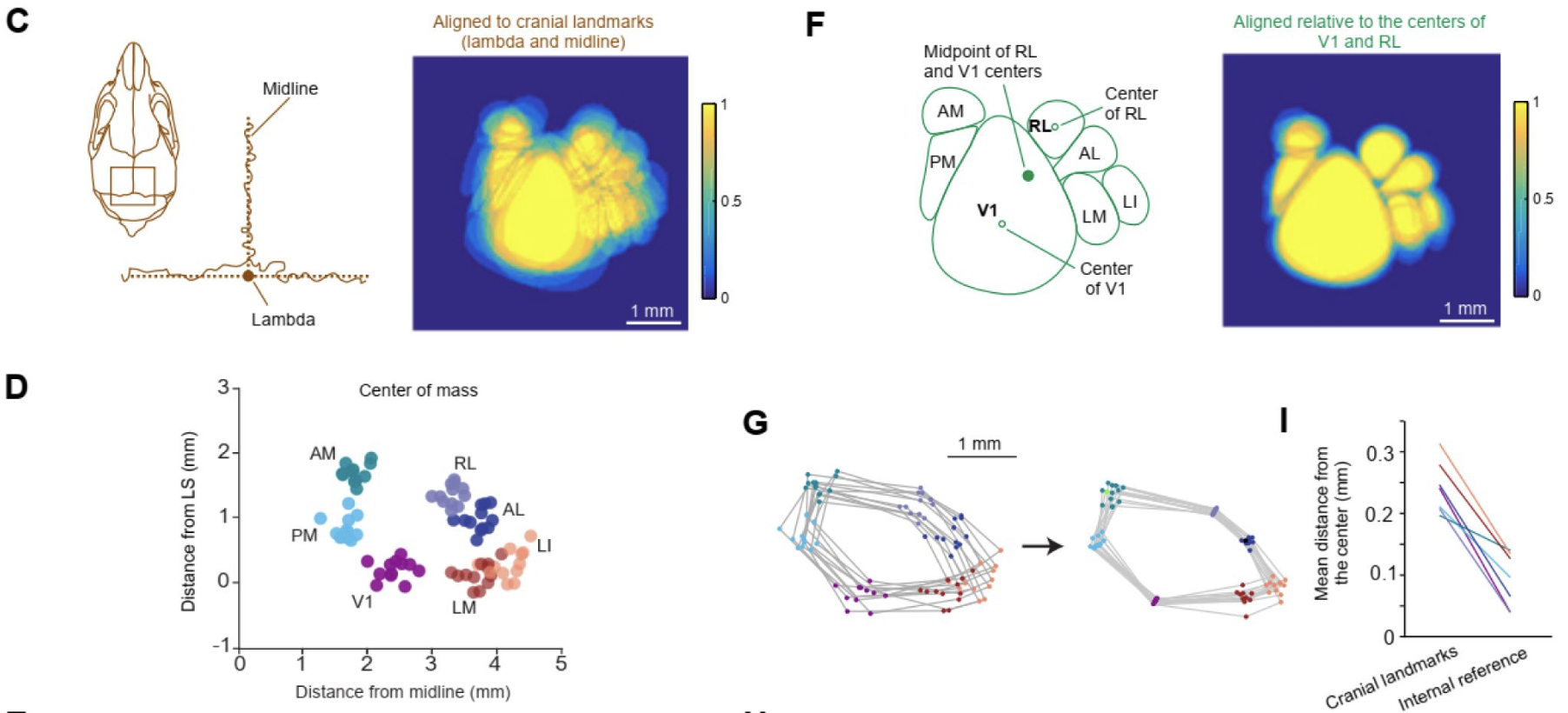
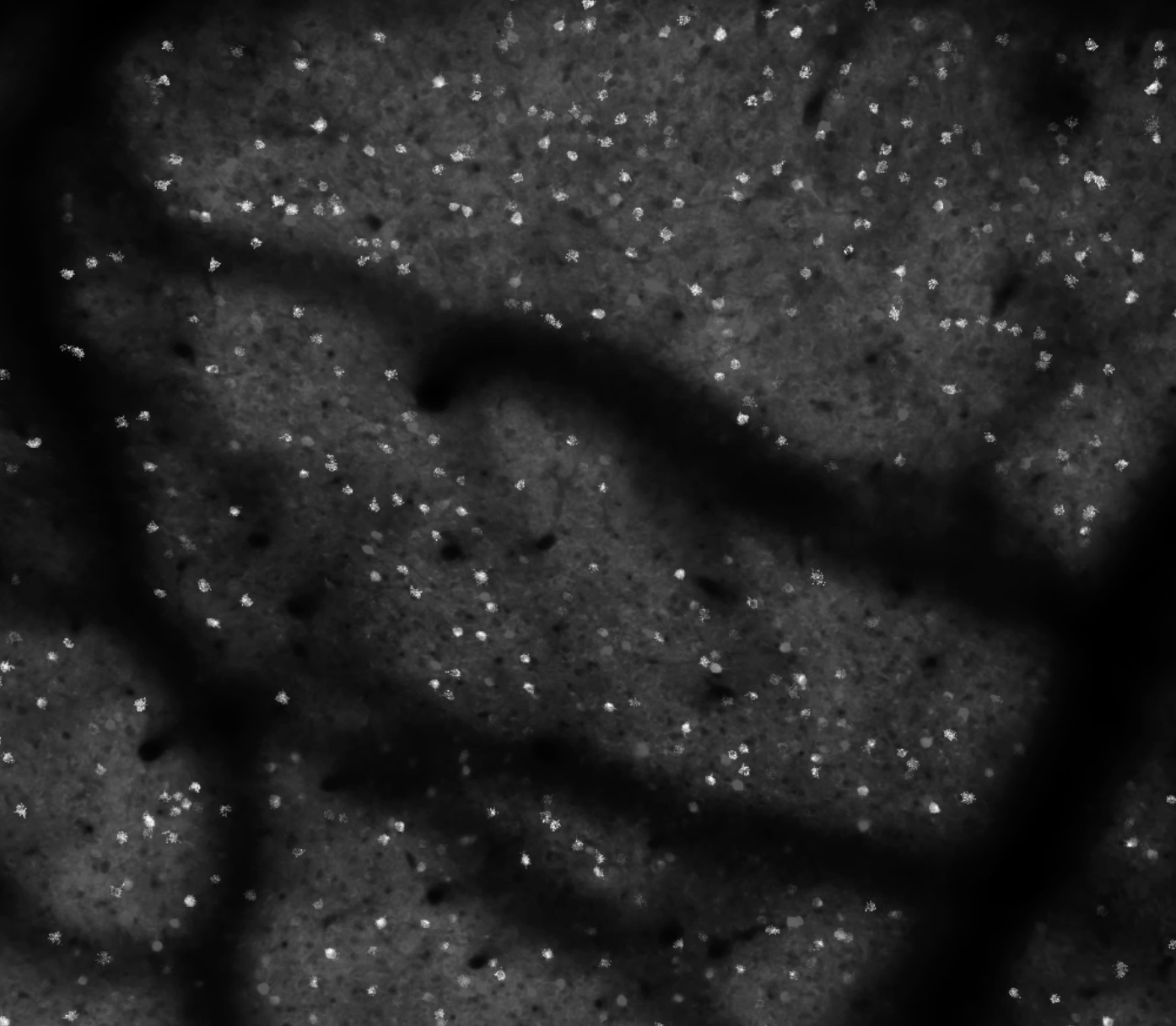
Functional landmarks in individual animals can be a better way to precisely identify cortical areas. Common landmarks, like skull landmarks, are okay for some applications, but not very precise. Especially for very small cortical areas < 0.5 mm across. For example, we provided this data in Riichiro’s recent eLife paper (this specific data and analysis was done by coauthor L. Townsend). Aligning to functional landmarks reveals highly regular mouse-to-mouse organization.
When you map things carefully, in individual animals, you can be very precise, and functional area borders can be quite striking. This is another figure from Riichiro’s paper (scale bar is 1 mm):
The rigor of the assignment of units to specific areas is one concern, another is the biases in extracellular recording and spike sorting. These biases can yield a dataset with relatively high spike rates, from similar neuron types, and these biases can influence the activity-based analysis, making the revealed relationships look more robust due to undersampling of more heterogeneous units.
Ultimately I disagree with the authors’ claim that “these findings challenge the traditional emphasis on cytoarchitecture, instead pointing to intrinsic connectivity as a primary organizing principle.” This is a false dichotomy. Of course connectivity matters, and the anatomists have taught us a tremendous amount about connectivity. The paper presents interesting analysis, with their self-organizing map (SOM) approach. There is definitely value in the paper and the work that the authors did. However, the paper does not provide strong evidence for the irrelevance of cytoarchitecture.
]]>0L.<![CDATA[Problems with system comparisons]]>https://labrigger.com/blog/?p=56672026-01-21T21:22:51Z2026-01-21T17:58:12Z
When you publish a paper on a new imaging system, people often want to compare figures of merit. Field-of-view, resolution, speed, etc. They want to know in what ways your system...
When you publish a paper on a new imaging system, people often want to compare figures of merit. Field-of-view, resolution, speed, etc. They want to know in what ways your system is better than other systems. Don’t take them at face value. They nearly always lack the rigor required to make the comparisons they present.
This paper (free pubmed pdf), with an excellent team led by Adam Packer, is the best resource to date for spec’ing a multiphoton imaging system. It’s less than a year old, and it should hold up over time fairly well.
There is a lot of good information in the paper– lots of technical details that are often omitted from methods sections. Check it out. Field-of-view, uniformity, resolution, sensitivity, and more.
The main problem is that the authors aren’t making the measurements of other systems. They’re just trying to glean specifications from papers. The numbers are almost never measured the same way, and often times aren’t even measured at all. So the authors just try to pull what they can from the papers. And of course, the authors are biased, so they will make judgement calls in favor of their system and against others.
Here are some examples:
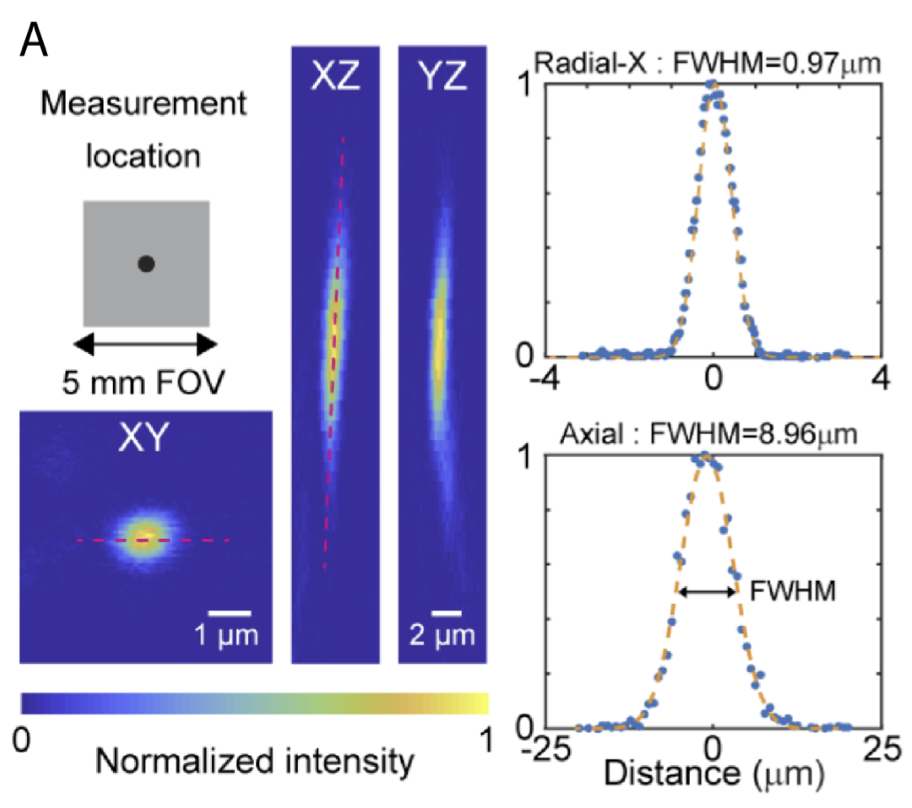
Resolution / point spread function (PSFs): If you’re unfamiliar with PSFs, see the section on spatial resolution here. The process for measuring PSFs isn’t always the same lab-to-lab. One thing I’ve seen is measuring PSFs that are tilted in the XZ or YZ planes with just a straight vertical line, which underestimates the full PSF extent. Look at the PSF graph at the top of this page. If you draw a vertical line in the YZ projection (right) that crosses through the maximum, you’ll get a smaller number than you do if you take the XZ projection and use a tilted line that captures more of the extent of the PSF. There are a bunch of different ways to measure PSFs. Some people will investigate and redo the measurement if it comes out bigger than they expect, but will just declare victory and move on if it is smaller than they expect. Thus, due to differences in process, it can be hard to compare small differences in PSFs across labs.
Depth: I’ve seen comparisons on imaging depth for multiphoton systems. However, almost no one makes rigorous measurements on imaging depth. They just take some images at a particular depth and that’s it. The comparisons are completely meaningless. The quality of images at depth are massively dependent on staining: brighter and sparser staining will make it easier to image deeper. Staining quality is by far the biggest determinate on how multiphoton images will look at depth. There is relatively little engineering that you can do to improve imaging at depth. There is a benefit to avoiding very high NA excitation in deep multiphoton imaging, which I discussed here. But for two systems that have similar NA, the performance is expected to be nearly indistinguishable. Higher collection NA should help, but even that is unclear, as the marginal rays don’t contribute to the overall signal as much as one might hope. “Most high angle skew rays entering the objective are simply lost in the barrel of the lens and never pass through the OBA [objective back aperture].”
So what these depth imaging comparisons are really doing is just comparing anecdotes between papers, which is meaningless. In our Trepan2p paper, we presented a video where we imaged down to 824 microns in vivo to see layer 5 cells. That was in a bright and sparsely labeled thy1 line which we had handy at the time. The Diesel2p system has higher NA, higher resolution, and is better in a ton of ways, but we didn’t present any data imaging deeper than 500 microns. Not because we couldn’t, but just because we didn’t have a preparation to image that was nice for that kind of imaging. A foolish comparisons of anecdotes would imply that the Trepan2p can image deeper than the Diesel2p, and that is wrong. Don’t fall for comparisons that are wrong. Look for rigorous assessments.
Imaging speed: Again, authors often use anecdotes for comparisons rather than rigorous measurements. They take some example imaging from one paper, field-of-view and frame rate, and then compare it to some example imaging from another paper. This is meaningless. They’re just comparing presented anecdotes. It’s easy to image fast over a large field of view and get useless data. It’s foolish to compare that low quality imaging mode to another paper where the authors zoomed in to have a lot of samples per neuron and get high fidelity measurements of fluorescence changes and carefully subtracted out the neuropil signals. Really, what people could compare is scan speed across systems with similar NA. For example, take two resonant scanning systems. Take the frequency of the resonant scanner, double it for bidirectional scanning, and then multiply it by the width of the resonant scan line. That’s a quantitative measurement that is actually pretty easy to take. It just requires a careful measurement of the width of the resonant scan line. And to be fair, it should be considered along with the excitation NA / resolution of the system.
Addendum: When reviewing a bunch of papers, it’s nice to focus on the figures of merit the papers were focused on. For example, the numbers that show up in the abstract, or were definitely a landmark and the authors had pushed for. Also, it’s good to cite prior work to highlight what’s new in a paper. But it is bad practice to undersell prior work. Once authors are trying to plot a bunch of prior work on 3 or more dimensions, they’re going to be making a lot of apples-to-oranges comparisons.
]]>0L.<![CDATA[It is Snel’s law, not Snell’s law, and actually really Sahl’s law]]>https://labrigger.com/blog/?p=56612026-01-17T20:58:43Z2026-01-17T20:58:43ZMaybe you learned that his name was Snell. It wasn’t.
Let me back up. Electromagnetic waves propagate at about 3 x 10^8 meters per second in vacuum. We often call that number “c“. When those waves have frequencies around 400 – 800 terahertz, we call them visible light.
When those waves go through materials like glass,...
]]>Maybe you learned that his name was Snell. It wasn’t.
Let me back up. Electromagnetic waves propagate at about 3 x 10^8 meters per second in vacuum. We often call that number “c“. When those waves have frequencies around 400 – 800 terahertz, we call them visible light.
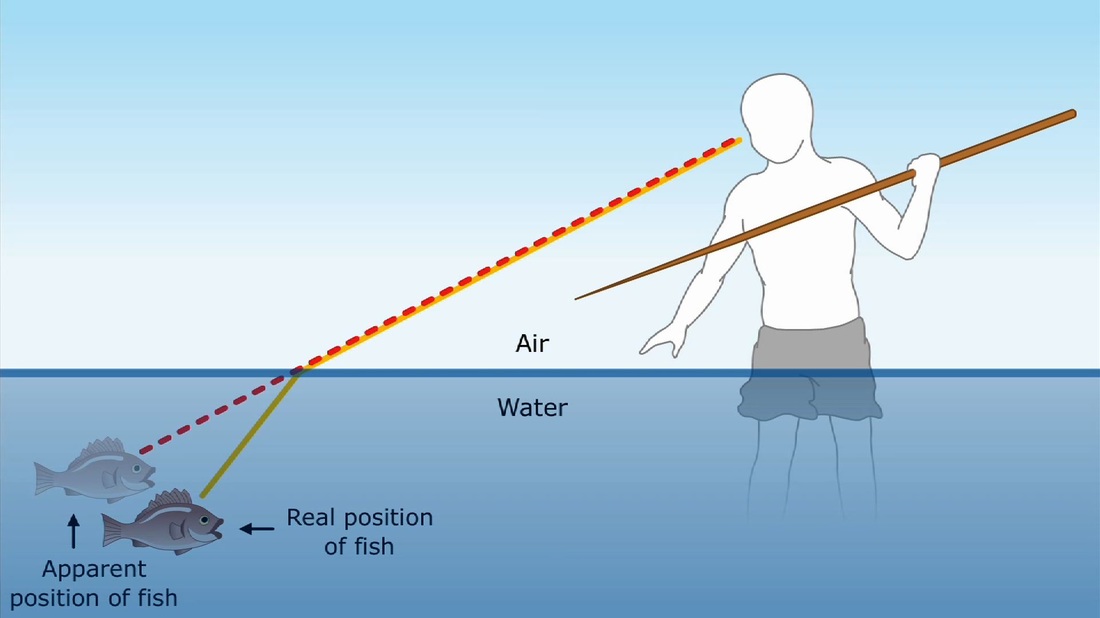
When those waves go through materials like glass, they slow down. Their speed is c/n, where n is typically > 1 and is called the index of refraction. When a light wave hits a surface at an angle, this decrease in speed leads also to a change in angle. You know this intuitively, just like people thousands of years ago did. You know as you look into water, the things you see under the surface of the water are a little bit deeper and closer to you than they look.
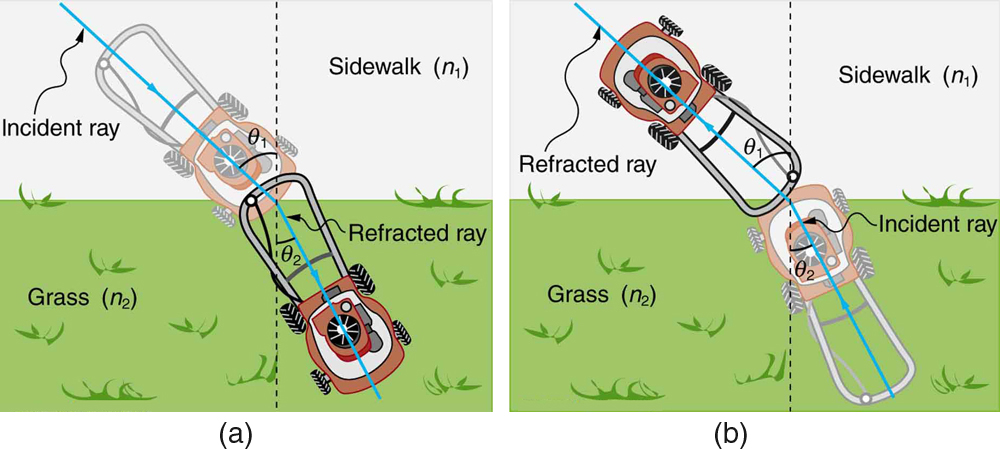
The image above probably works great if you have experience with successful spearfishing. But if not, maybe you’ve mowed a lawn? This diagram does a good job of explaining it too. Maybe this intuition works better for some people.
However, the fellow was born with the name Willebrord Snel van Royen. Just one “L”, not two. Where did the second “L” come from? I’m glad you asked.
It was fashionable at the time to Latinize one’s name. Latin names sounded cooler. They worked better across countries. Latin was a common denominator. People have been electing to change their names throughout history (e.g., when immigrating to another country) and still do today. For example, people who pick a common English name because their given name is hard for English speakers to pronounce.
Willebrord latinized his last name to Snellius. Then, someone shortened it to Snell. Who did that?
Well, Snel / Snellius died kind of young, at age 46. He didn’t get around to publishing everything he had done. His precise mathematical description of the law that bears his name (in some form), was found and published by Christiaan Huygens, who decided to drop the last two letters from the Latinized form and credit him as “Snell”. That’s why we spell his name that way today.
By the way, Christiaan Huygens also got in on the Latinization craze, and dubbed himself Christianus Hugenius. But is perhaps better known by his non-Latinized name.
And several other people hit upon the same law around the same time in the 1600s: Thomas Harriot, Rene Descartes, and Pierre de Fermat.
This handbook is available for free online. Here’s the link.
There is much evidence that updates to factual beliefs, even if successful, may not translate into attitude or behaviour change. For example, in polarized societies (e.g., the U.S.) people indicate that they will continue to vote for their favored politician even if they discover that the majority of the politician’s statements are false [21, 22, 23]. Fortunately, it does not have to be that way. In less polarized societies (e.g., Australia), people’s voting intentions are sensitive to politicians’ truthfulness [24]. Nevertheless, do not refrain from debunking because you are worried it will not change behaviour. Successful debunking can affect behaviour—for example, it can reduce people’s willingness to spend money on questionable health products or their sharing of misleading content online [25, 26].
]]>0L.<![CDATA[“Listen to me. I’m unconvincing.” -someone]]>https://labrigger.com/blog/?p=56522026-01-14T22:58:34Z2026-01-14T22:58:33Z
There are always people who complain loudly that they are unconvincing. They won’t say it that way, though.
Instead, they might blame suppression of speech, or a conspiracy, or people being paid-off, or...
There are always people who complain loudly that they are unconvincing. They won’t say it that way, though.
Instead, they might blame suppression of speech, or a conspiracy, or people being paid-off, or other nonsense. But the truth is simple: their evidence isn’t convincing.
Science progresses when scientists produce evidence and persuade each other.
]]>0L.<![CDATA[Rigor for everyone]]>https://labrigger.com/blog/?p=56462025-12-29T21:01:05Z2025-12-29T11:33:00Z
It’s right there in the name of this blog. A double entendre: (1) for experimental apparatus rigs and the people who build them, aka “riggers”; and (2) rigor, an important principle,...
It’s right there in the name of this blog. A double entendre: (1) for experimental apparatus rigs and the people who build them, aka “riggers”; and (2) rigor, an important principle, both generally and specifically in scientific research. I guess it’s a homophone then (rigor/rigger)? Or both a homophone and a double entendre? At any rate, it’s a paronomasia.
In scientific research, I am interested in how we can avoid fooling ourselves. Scientists are, by training and nature, appreciative of evidence, quantified uncertainty, and updating models or beliefs. Still, we aren’t perfect, and there’s room for improvement. For example, how can we avoid letting entire fields wander off into areas that lack a firm, rigorous foundation?
More generally, in everyday affairs, policy and politics, there is also room to enhance our rigor. This is a somewhat thornier thing to me. How do we equip ourselves and our neighbors to not fool themselves? What are the antidotes to charlatans, conspiracy theories, and other nonsense?
I’m haunted by the discussions I had with my father. He passed away years ago, but today would have been his 78th birthday. (The photo here is of the private airfield he liked to fly out of. He flew single engine planes as a hobby.) He was fascinated by science and engineering, was an excellent programmer and rigorous thinker in many ways, but he was still vulnerable to charlatans, conspiracy theories, and other nonsense. I assume that I am not invincible either, which is part of the point I’m making. Humans may vary in our susceptibilities, but I doubt that very many of us are truly immune.
I talked to my father about how scientists value evidence and precise discussions of uncertainty. He was receptive, and appreciated the point, but still, he loved searching for evidence and arguments that upheld his beliefs rather than challenging them. Many people do.
Ultimately, raw evidence isn’t enough. The advance of human science and technology is a social enterprise, as one must get eyeballs on their work and evidence, and then persuade the viewers that their evidence is enough for the audience to update their models or beliefs. 1. Evidence. 2. Attention. 3. Persuasion. People can skip over the first step, and simply garner a big audience and persuade them with a lot of hot air, filling in the evidence later– often with a lot of the window dressing of scientific rigor, which only specialists in the field would see through. This leads us to situations where conspiracy theories take hold, and disagreements on facts, history, and current events drive people apart, with each feeling righteous, and evidence-based.
Do you have thoughts one how we address this? Accountability is one way. What are some other practical strategies?
]]>0L.<![CDATA[Autonomous vehicles vs. mice vs. bouncy balls]]>https://labrigger.com/blog/?p=56422025-12-21T05:43:59Z2025-12-21T05:43:58Z
I have a little piece I often reuse, it goes something like this.
We know that visually guided navigation is a hard problem even for state-of-the-art AI because we’re pouring...
I have a little piece I often reuse, it goes something like this.
We know that visually guided navigation is a hard problem even for state-of-the-art AI because we’re pouring billions of dollars into R&D for self-driving cars and they still fail in situations where novice drivers don’t. Waymo is pretty good, but they have tons of cameras, lidar, and radar units. Tesla is going vision-only, and nearly always has to be supervised, despite an array of high resolution cameras and kilowatts of on-board processing power. And regardless, in all cases this is just for highly stereotyped roads and places that are designed for vehicles.
By contrast, running on less than 1 watt of power, and in a fraction of a second, a mouse can navigate to a place in this room where it can get to and I can’t. It won’t make any mistakes. It won’t run into a wall. It won’t go in pointless loops. Despite how unnatural, how out-of-distribution it is, despite how poor the resolution of mouse vision is, they will recognize their affordances and navigate to a place where they can get to and I can’t.
I think this is a pretty compact way of describing a visual navigation problem and highlighting how evolution has led to animals that are wonderful at generating robust behavior to solve the problem. Yet humankind still has not.
I use this piece a lot. Too often, to be honest, but it’s useful to me.
Then, one day, my wife Prof. Ikuko Smith, DVM PhD, said, “Our daughter can throw a small bouncy ball in this room and often get the same result. It will end up under a couch or table or someplace it can get to and you can’t.”
Goddammit. That’s an excellent evisceration of my thesis. How did I ever convince a person like her to pair up with me?
Sure, the bouncy ball is inanimate, and it will often come to rest in an easy-to-access location. But I love the point. The algorithm needn’t be very complex.
It reminds me of when my father and I were watching sanderlings on the beach in Santa Barbara (not my video, but if you’re curious). I had just started graduate school at UCLA and he flew out to hang out with me for a bit. I didn’t know what to do, as I had just moved to California myself, but I remembered that he had visited Santa Barbara when I was a kid, so we drove up there. And now I live here.
I said that I was impressed at how precise and reliable the birds were at navigating the waves. People would get drenched by waves occasionally, but the birds seemed to know right when to retreat, and when to venture far down the shore. My dad listened patiently, and then said something like, “It’s maybe not that hard of a calculation, they’re just used to it. They know what it should look like, and they have lots of practice.” It was a down-to-earth, common sense take. Maybe it’s hard to me, and I’d knock myself out developing an algorithm to reproduce the behavior, but that doesn’t mean it’s actually hard. Just like humankind learned with visual object/character identification, through Imagenet/Alexnet. It’s not actually that hard, you just need a more organic system (e.g., a CNN). Tons of training data + backprop can help you design the system, but however you get to the solution, the end implementation (ie, inference time) is not that hard.
I hope to hit upon a similar insight with the mouse vs. AI stuff we’re doing. Generating robust behavior in complex settings is maybe not that hard, but until you have the recipe, it seems hard. Let’s figure out how to make the system.
]]>0L.<![CDATA[DIY synth for circuits and signal processing]]>https://labrigger.com/blog/?p=56362025-12-11T17:06:21Z2025-12-11T17:04:30Z
I came across this cool minimal synth kit called Labor from Erica synths. It’s great for learning about circuits and signal processing. There are videos online about...
I came across this cool minimal synth kit called Labor from Erica synths. It’s great for learning about circuits and signal processing. There are videos online about it to get started. It looks great!
When I was a kid, maybe around 8 years old, I had a couple of toy like this, and they taught me a lot of basic rules and intuitions about circuits and signal processing. One was a Radio Shack electronics experiments kit, and the other was some sort of sound effects generator with lots of knobs and switches. Those toys and the mini notebooks by Forrest M. Mimm III gave me a lot to experiment with and learn from. This Labor synth could set a lot of people on a good trajectory for learning about circuits and signal processing too. In a fun way that connects with music as well, for those who might be into that. Some of the circuit design/analysis would be appropriate even for high school or early college circuit classes.
]]>0L.<![CDATA[Building a two-photon microscope is easy]]>https://labrigger.com/blog/?p=56322025-12-02T22:41:55Z2025-12-02T22:41:54Z
One time, years ago, I was asked (by a very nice person and an accomplished scientist) to write a book chapter. I didn’t want to. But I was working with a brilliant postdoc who might...
One time, years ago, I was asked (by a very nice person and an accomplished scientist) to write a book chapter. I didn’t want to. But I was working with a brilliant postdoc who might enjoy the project and we could do it together, and so I asked him. He said sure, so I agreed to do it. Then that postdoc moved on and the book chapter didn’t get written. It wasn’t even drafted. But the deadline was still approaching. I explained the situation, but my very kind colleague still encouraged me to write it. So the challenge was this: How can I get this job done as quickly as possible while still adding something of value?
I decided to write a very compact description of what it is to build a two-photon laser scanning microscope. It is basically a confocal microscope with no pinhole. The laser is really doing the heavy lifting. The optics can be optimized, but even mediocre optics can provide some decent performance. There’s no need to reinvent the wheel, and there’s no need to get too picky about it. The optics work we’ve done in the lab, and we continue to do both in the lab and the company, is quite finicky and detailed and time-consuming. But if you just need to get oriented and get the basics, there’s no reason to get lost in the weeds. Anyone can do this. This is 1980s era DIY. This is early punk. Let’s distill this craft to its essence. (But still, I don’t have all damn day, so I need to get this off my desk.)
The result was this (PDF link). I was just looking over it, prepared to be embarrassed, and I actually quite like parts of it. Maybe it merits mentioning it here. If you have someone new to two-photon imaging, it might not be a bad place to start. After this, there are a bunch of papers that get into the nitty gritty of building a system, a few of which can include this book chapter, this other book chapter, this article, and these two morerecent articles.
]]>0L.<![CDATA[Entire fields on poor foundations]]>https://labrigger.com/blog/?p=56202025-11-13T20:12:04Z2025-11-13T20:03:11Z
It has been a long standing interest of mine to better understand (and find ways to address) how entire fields of scientists can lead each other astray– into ideas that...
It has been a long standing interest of mine to better understand (and find ways to address) how entire fields of scientists can lead each other astray– into ideas that have no solid foundation. A volume of studies can reinforce each other in a positive feedback loop, with no one critically assessing the foundation, and any critical analysis being dismissed.
Part of this is just the natural course of humans doing science, and the self-correcting nature of the process can take time.
Plus, add in all the foibles of human reasoning, relationships, and echo chambers…
Plus, add in incentive structures that discourage disowning one’s own prior work…
It’s not surprising that these things happen. But they waste resources– the time and brain power of smart, hardworking people, and money, animals, etc. So if there are ways that we can better detect when such dynamics are in play, it can overall help the enterprise of science.
I’m not talking about fraud, whether brazen fabrication or softer p-hacking. That’s important to combat too. I’m talking about insufficient rigor, and not just in individual studies. An individual study can be rigorous, but based on a foundational idea that lacks rigorous evidence. The foundation is poor, and people keep building upon it. The building — paper after paper after paper, new PhDs trained, grants, studies — all continue, perpetuated by positive feedback mechanisms, despite the fundamental limitations of the conceptual foundation of the entire field.
This foundational problem is a bit harder to nail down than fraud. Although fraud can be well hidden, and I appreciate the heroic efforts to uncover it, the idea is straightforward: presenting evidence that isn’t real.
When there is a lack of foundational rigor, left in place and built upon by well intentioned people, it can be in plain sight, but hard to nail down. And since it is typically coming from well intentioned people, who are being honest and open for the most part, it’s not fun to be critical about it. It’s not like dunking on obviously fraudulent image manipulation via an anonymous PubPeer post. Again, I appreciate that work and the people who do it (e.g. E. Bik), but what I’m talking about here is not as easy to identify and address.
I’m not a microbiome researcher, but I care about the phenomenon they’re addressing. And they do so masterfully here. The whole thing is very readable, and it’s open access. Check it out. Kevin Mitchell, Darren Dahly, and Dorothy Bishop make very clear points about the problem I describe at the top of this post. Some of their points are specific to the field they’re discussing (microbiome – autism links), but many are more general.
Here I’ll share some of my thoughts– cribbed from my Slack messages this morning as I live-streamed my thoughts while reading it. I’m going to stick to the points of general relevance. I’m not going to dig into their criticism of specific studies.
Here’s the abstract: “The idea that the gut microbiome causally contributes to autism has gained currency in the scientific literature and popular press. Support for this hypothesis comes from three lines of evidence: human observational studies, preclinical experiments in mice, and human clinical trials. We critically assessed this literature and found that it is beset by conceptual and methodological flaws and limitations that undermine claims that the gut microbiome is causally involved in the etiology or pathophysiology of autism.”
The authors are calling out the lack of foundational rigor in the field that works to link gut microbiomes with autism spectrum disorder. And they are trying to be precise and clear in identifying the positive feedback mechanisms that are perpetuating the field, despite the lack of foundational rigor. They use a couple of terms “pseudo-triangulation” and “quasi-replication”. They explain what those mean, and I think they’re useful terms. Whether they catch on is up to everyone else.
“pseudo-triangulation,” building an appearance of convergence from incommensurate and individually unconvincing lines of evidence.
“quasi-replication,” where any difference in the microbiome is taken as adding to the evidence base of a real effect, even when the details are inconsistent or even contradictory.
“The sense is that the literature is not cumulative, with later studies replicating and building upon earlier ones; rather, the rationale for a study is that ‘‘something is going on’’ in relation to autism and the gut microbiome, with each study adopting different methods and no consistent, replicable findings emerging.”
First, they discuss alternative hypotheses which are not necessarily well considered in the literature. For example, the genetic differences that lead to a diagnosis for autism can also lead to problems elsewhere in the body. This happens all the time in genetic diseases. So, fundamentally, a field should weigh competing or alternative hypotheses before accepting one.
Next, they discuss issues with large scale data mining studies. There are methodological details such as process and the choice of controls, confounders, effect sizes, etc. But also, by their nature, these are exploratory studies that can end up looking like strong evidence for a specific idea. But finding differences in data minding studies is easy. And just because multiple studies find differences, are they really reinforcing each other? Are they building on each other? Is this an accumulation of evidence?
“This body of work continues to be cited uncritically, however, deepening the perception of a solid evidence base. The inference seems to be that, even if specific findings are inconsistent, most of the (published) studies that have examined the question have found some differences in the microbiome of autistic people compared with TD [typically developing] controls. This is often couched in more general terms with claims of ‘‘dysbiosis’’ of the gut microbiome in individuals with autism. As pointed out by researchers in the field, this is a vague term, which effectively captures any profile of differences, regardless of consistency. [13,14] Two studies showing directly contradictory profiles of change could both be classed as evidence of dysbiosis.”
Then there is a lot of criticism of mouse models for autism research, and I agree with some of it. I have a bit to say about this topic, but I won’t do it here in this blog post, because I want to stick with the more generally applicable stuff.
Getting back to exploratory work… I appreciate exploratory work. And the rigor bar is lower for those kinds of studies. They’re important, and by their nature they definitely shouldn’t pre-register their hypotheses. They should explore and see what they find.
What sometimes happens is exploratory work evolves into something else. And that’s a problem. Here are two examples of what can happen: (i) Other people cite an exploratory study with a statistically significant measurement as strong evidence for “A causes B”, even though the original paper is much more muted in its claims. In this case, the problem lies with the people citing the study. (ii) The desire for a high profile publication pushes the authors to make stronger claims than their study design justifies. In this case, the authors need to be accountable as well as the people who cite it uncritically.
“The big data generated in microbiome studies lend themselves to numerous possible analyses, such that if one looks hard enough, something is bound to emerge, especially in studies with very small samples. Flexibility also characterizes the hypotheses that are considered. A typical study starts with the notion that there is some link between autism and the microbiome but is vague in terms of the specific hypothesis being tested, so that what we see is hypothesizing after results are known (HARKing).[143]”
This pull quote really nails it, and the same can be said about many fields that have a sort of positive feedback loop that keeps them going despite the lack of a strong, rigorous foundation:
“Taking this literature as a whole, there may be a sense that ‘‘where there’s smoke, there must be fire,’’ but experience from other fields (social psychology, candidate gene association studies, neuroimaging association studies, and nutritional epidemiology) has shown that actually there can sometimes just be lots of smoke. Though diverse results from different studies are often presented as a kind of quasi-replication (where the details vary but something was found), in fact, each such study could be taken as a non-replication of the findings of many other studies.”
In this particular case, there is a human cost that needs to be considered and weighed carefully:
“This hype is not without consequences. It feeds on, and feeds into, narratives of an epidemic of autism caused by environmental factors that can be addressed with ‘‘natural’’ remedies promoted by a largely unregulated global wellness industry. The general public is not well equipped to evaluate these claims and are vulnerable to being taken advantage of, especially with respect to autism.”
At the end, they provide some constructive advice. And this is what I hope has impact on the field, so it is a pity it is buried at the end and not even alluded to in the abstract. They say, in part:
“for those who think this topic is worth taking further, it would make sense to adopt some ground rules. In many ways, these would be similar to those adopted by geneticists after the first frenzy of candidate gene associations was found to be a waste of time and money because the area was overwhelmed by nonreplicable false positive results. [147] The solution was an increase in experimental rigor, with requirements for adequate statistical power, standardized protocols, and a clear distinction drawn between exploratory and confirmatory studies.”
Want to make your calcium imaging videos look better for presentations? Read on. Or just skip to the recipe section below. First, I’ll discuss the motivation a bit.
Want to make your calcium imaging videos look better for presentations? Read on. Or just skip to the recipe section below. First, I’ll discuss the motivation a bit.
One of my refrains when I talk about making slides for scientific presentations is: “Never tell your audience, ‘this is hard to see, but it looks okay on my laptop’.” We’ve all heard some version of that many times. It’s natural and understandable, but it’s also avoidable. Show respect to your audience by preparing in advance.
Unless you’re giving a talk on something excellent like an 8k high dynamic range OLED monitor, all of your slides are definitely going to look poor compared to your laptop display. Very low contrast. Count on it. Expect it. Plan for it.
All of your images need to have very high contrast. Test them out on the worst projector you can find. Like a cheap VGA mini projector you buy on the internet for fifty bucks. Make sure that they look good on that. THEN go give your talk.
I show a lot of two-photon calcium imaging videos in my talks. It’s a big part of how I study neural circuitry. These videos are beautiful to me. Perception and behavior, all of our experiences and interactions with the world, are built from countless tiny millisecond-long millivolt-level excursions. These vast conversations, spanning the entire brain every second, are an insanely beautiful choreography. And large field-of-view two-photon calcium imaging distills this computational choreography into visible light.
The type of calcium imaging I do prioritizes the field-of-view and temporal resolution. I want as many neurons as I can sample, at around 10 frames per second, with each neuron having enough samples to provide a high fidelity measurement of the fluorescence dynamics of a calcium indicator. The spatial sampling is typically well below the Nyquist criterion, because I don’t care about the shape of cells. I just need enough pixels per neuron to get a high fidelity signal (often this is 10-20 pixels). We are often operating in the regime where shot noise is a visible factor, making due with as few photons per pixel as we can, so that we can distribute them broadly in space and time, and obtain sufficient temporal resolution for as many neurons as possible.
So the individual frames can be a bit ugly. That’s okay. They are a bit noisy. We’re averaging over all of the pixels for individual cells before we do our analysis. The individual frames can look pretty rough, and we still get high fidelity measurements of indicator dynamics from them. So while the aficionados can see the beauty in raw calcium imaging videos, a general audience might be less impressed. They might wonder what we’re so excited about. It can be helpful to process the videos to give a better impression of the data.
Sometimes simply adjusting the look-up-table parameters (min and max values, and gamma) can help a lot. Perhaps a snappy color look-up-table can help. I typically prefer to stick with black-and-white for this type of data. Colored look up tables can lead to unpredictable results with color reproduction on projectors, low contrast, and/or colorblind audience members. Black-and-white is a bit more general purpose, and can be sufficient in many cases.
Recipe
Let’s think about this problem another way. Like I said above, the individual frames can be sort of ugly and that’s okay because we average signals over the pixels assigned to individual cells. This leads to high fidelity signals that we use for analysis. Instead of asking the audience to have the eyes of an aficionado and recognize the quality of the raw data, let’s go ahead and do the analysis and then map that back into the video.
First, let’s analyze the data. Apply motion correction, segment the image, extract the raw traces, do the neuropil subtraction, and infer spikes. Hold on to that for a moment.
Second, let’s take a projection of the video stack. Either a max, average, or std dev projection. Whatever looks good. Sometimes it’s better to run the projection on a subsection of the stack, not the full stack.
Third, let’s work backwards. Take the inferred spike trains and convolve them with a calcium indicator kernel (near-instantaneous onset and an exponential decay). Then use those convolved signals to modulate the brightness of the ROIs mapped back onto the projected image.
Filip Tomaska worked on this idea and wrote the code to work things out. At first, we used binary ROI masks, and that was okay, but looked a bit crude and pixelated. Using a max projection of the ROI gave us some shading that looked a bit more pleasing. Another thing we did is make the projection a bit dim, so that bright cells can pop out better when they increase in brightness over time.
Last of all, we adjusted the function for mapping the signal trace to ROI brightness. A straight linear mapping is a problem because single spike signals are hard to see by eye, and the bursts are relatively rare. So it gives the impression that there is less activity than we can actually detect. Projectors and displays often only have 8 bits of dynamic range for brightness and can be effectively worse depending on ambient lighting. The actual signals we use for analysis can have 12+ bits of dynamic range. So for display I wanted a function that would be linear at low values, to make single spikes visible, and then quickly saturate at high values. The hyperbolic tangent (tanh) function worked well for that. Here’s the end result:
And here’s the code by Filip Tomaska (below). We use Suite2p and MCMC for spike inference. This code takes in a mean image, stat, and iscell from Suite2p + spiketimes from MCMC.
function overlayBlinkingROIs_onMean(meanIm, out, stat, iscellFlags, varargin)
% Overlay blinking ROIs (alpha ~ convolved spikes) on a mean projection.
%
% Inputs
% meanIm : [Ly x Lx] mean projection (double/single/uint)
% out.path1_phys.spiketimes :
% - cell array: {k} seconds
% - struct array: (k).spks seconds (your case)
% Count must equal sum(iscellFlags(:,1)==1)
% stat : Suite2p ROI struct(s): stat{1,i}.xpix/ypix or stat(i)
% iscellFlags : [Nroi x 2], first col 1 = cell, 0 = not cell
%
% Name/Value options
% 'Params' : struct('tau_rise',0.07,'tau_decay',0.7) (default)
% 'FPS' : native fps of original acquisition (default 15)
% 'DurationSec' : total duration to render (default: from last spike + margin)
% 'NFrames' : override number of frames (else computed from DurationSec)
% 'Output' : output MP4 filename (default 'roi_on_mean_2x.mp4')
% 'BaseContrast' : [low high] percentiles for base image (default [1 99])
% 'ClipPercent' : soft-clip traces percentile (default 99)
% 'GlobalScale' : normalize traces by global max (default true)
% 'OverlayColor' : [R G B] single color (default [0 1 0])
% 'ColorByROI' : true = distinct colors per ROI (default false)
% 'AlphaMax' : max overlay alpha (default 0.85)
%
% Example
% params = struct('tau_rise',0.07,'tau_decay',0.7);
% overlayBlinkingROIs_onMean(mean(M1,3), out, stat, iscell, ...
% 'Params', params, 'FPS', 15, 'Output','blink_on_mean.mp4');
%^by chatGPT for better dissemination
% parse options
p = inputParser;
p.addParameter('Params', struct('tau_rise',0.07,'tau_decay',0.7));
p.addParameter('FPS', 15);
p.addParameter('DurationSec', []);
p.addParameter('NFrames', []);
p.addParameter('Output', 'roi_on_mean_2x.mp4', @ischar);
p.addParameter('BaseContrast', [1 99], @(v)isnumeric(v)&&numel(v)==2);
p.addParameter('ClipPercent', 99, @(x)isnumeric(x)&&isscalar(x)&&x>0&&x<=100);
p.addParameter('GlobalScale', true, @islogical);
p.addParameter('OverlayColor', [0 1 0], @(v)isnumeric(v)&&numel(v)==3);
p.addParameter('ColorByROI', false, @islogical);
p.addParameter('AlphaMax', 0.85, @(x)isnumeric(x)&&isscalar(x)&&x>=0&&x<=1);
p.parse(varargin{:});
opt = p.Results;
% kernel params (support params.'6s' style too)
params = opt.Params;
if isfield(params,'tau_rise') && isfield(params,'tau_decay')
tau_rise = params.tau_rise; tau_decay = params.tau_decay;
elseif isfield(params,'6s')
tau_rise = params.('6s').tau_rise; tau_decay = params.('6s').tau_decay;
else
error('Params must have tau_rise/tau_decay or a key like params.''6s''.');
end
fps_native = opt.FPS;
% ?? select ROIs (only iscell==1) and grab spikes container ?????????????????
roiIsCell = find(iscellFlags(:,1)==1);
nKeep = numel(roiIsCell);
if ~isfield(out,'path1_phys') || ~isfield(out.path1_phys,'spiketimes')
error('out.path1_phys.spiketimes not found.');
end
spkBag = out.path1_phys.spiketimes; % may be cell array or struct array
isSpkCell = builtin('iscell', spkBag);
isSpkStruct = isstruct(spkBag);
if numel(spkBag) ~= nKeep
error('spiketimes count (%d) != number of iscell==1 (%d).', numel(spkBag), nKeep);
end
% helper for spike times (seconds) per kept index k
get_spikes = @(k) local_get_spikes(spkBag, k, isSpkCell, isSpkStruct);
% get image size, roi etc...
[Ly,Lx,zeroBased] = local_infer_image_size(stat, iscellFlags);
maskIdx = cell(nKeep,1);
for k = 1:nKeep
roi = roiIsCell(k);
S = local_stat_at(stat, roi);
y = S.ypix(:); x = S.xpix(:);
if zeroBased, y = y+1; x = x+1; end
y = max(1, min(Ly, round(y)));
x = max(1, min(Lx, round(x)));
maskIdx{k} = sub2ind([Ly Lx], y, x);
end
% process mean projection
%
meanIm = im2double(imresize(meanIm, [Ly Lx]));
lo = prctile(meanIm(:), opt.BaseContrast(1));
hi = prctile(meanIm(:), opt.BaseContrast(2));
baseIm = (meanIm - lo) / max(hi - lo, eps);
baseIm = min(max(baseIm,0),1);
% infer timeline from last spike time
if ~isempty(opt.NFrames)
nFrames = opt.NFrames;
else
if ~isempty(opt.DurationSec)
Tsec = opt.DurationSec;
else
lastSpike = 0;
for k = 1:nKeep
st = get_spikes(k);
if ~isempty(st), lastSpike = max(lastSpike, max(st)); end
end
Tsec = lastSpike + 5*max(tau_decay,tau_rise); % tail margin
if ~isfinite(Tsec) || Tsec<=0, Tsec = 10; end % fallback 10s
end
nFrames = max(1, round(Tsec * fps_native));
end
dt = 1 / fps_native;
t_edges = 0:dt:(nFrames*dt);
% GECI kernel
tmax = 5*max(tau_decay, tau_rise);
kt = 0:dt:tmax;
kern = exp(-kt./tau_decay) - exp(-kt./tau_rise);
kern = max(kern, 0);
if max(kern)>0, kern = kern./max(kern); else, warning('Kernel is zero.'); end
% convolve spikes to Ca
traces = zeros(nKeep, nFrames, 'single');
globalMax = 0;
for k = 1:nKeep
st = get_spikes(k);
if isempty(st), continue; end
bcounts = histcounts(st, t_edges); % length nFrames
convsig = conv(single(bcounts), single(kern), 'same');
traces(k,:) = convsig;
if opt.GlobalScale, globalMax = max(globalMax, max(convsig)); end
end
if opt.GlobalScale
traces = traces / max(eps, globalMax);
else
for k = 1:nKeep
m = max(traces(k,:)); if m>0, traces(k,:) = traces(k,:)/m; end
end
end
traces = min(max(traces,0),1);
if opt.ClipPercent < 100
v = traces(:); v = v(v>0);
if ~isempty(v)
vmax = prctile(v, opt.ClipPercent);
if isfinite(vmax) && vmax>0, traces = min(traces / vmax, 1); end
end
end
% overlay color def
if opt.ColorByROI
cmap = hsv(nKeep);
else
cmap = repmat(opt.OverlayColor(:).', nKeep, 1);
end
% write as mp4 because boss hates avi.
playback_coeff = 2: % how many times faster is the playback
fps_out = playback_coeff * fps_native;
vw = VideoWriter(opt.Output, 'MPEG-4'); vw.FrameRate = fps_out; vw.Quality = 95; open(vw);
fprintf('Writing %s (%dx%d), %d frames @ %.1f fps (2×)...\n', opt.Output, Lx, Ly, nFrames, fps_out);
for f = 1:nFrames
% start with static base
frameRGB = repmat(baseIm, [1 1 3]);
% alpha-blend each ROI using trace as alpha driver
for k = 1:nKeep
a = min(1, opt.AlphaMax * double(traces(k,f)));
if a<=0, continue; end
idx = maskIdx{k};
for c = 1:3
col = cmap(k,c);
tmp = frameRGB(:,:,c);
tmp(idx) = (1 - a).*tmp(idx) + a.*col;
frameRGB(:,:,c) = tmp;
end
end
writeVideo(vw, im2uint8(frameRGB));
end
close(vw);
fprintf('Done.\n');
end
%helpers
function S = local_stat_at(stat, ii)
if builtin('iscell', stat), S = stat{1,ii}; else, S = stat(ii); end
end
function [Ly,Lx,zeroBased] = local_infer_image_size(stat, iscellFlags)
nROIs = size(iscellFlags,1);
allY = []; allX = [];
for ii = 1:nROIs
S = [];
if builtin('iscell', stat)
if ii<=numel(stat) && ~isempty(stat{1,ii}), S = stat{1,ii}; end
else
if ii<=numel(stat) && ~isempty(stat(ii)), S = stat(ii); end
end
if ~isempty(S) && isfield(S,'ypix') && isfield(S,'xpix') ...
&& ~isempty(S.ypix) && ~isempty(S.xpix)
allY = [allY; S.ypix(:)];
allX = [allX; S.xpix(:)];
end
end
if isempty(allY) || isempty(allX)
error('Could not infer image size: stat entries missing ypix/xpix.');
end
zeroBased = (min(allY) == 0) || (min(allX) == 0);
Ly = max(allY) + double(zeroBased);
Lx = max(allX) + double(zeroBased);
end
function st = local_get_spikes(spkBag, k, isSpkCell, isSpkStruct)
if isSpkCell
st = spkBag{k};
elseif isSpkStruct
if isfield(spkBag, 'spks')
st = spkBag(k).spks;
else
cand = {'t','times','spike_times','spikeTimes'};
got = [];
for ii=1:numel(cand)
if isfield(spkBag, cand{ii}), got = spkBag(k).(cand{ii}); break; end
end
if isempty(got), error('spiketimes struct lacks .spks (or known aliases).'); end
st = got;
end
else
error('out.path1_phys.spiketimes must be cell or struct array.');
end
if isempty(st), st = []; else, st = st(:)'; end
end
]]>3L.<![CDATA[Accountability is a way to determine truth]]>https://labrigger.com/blog/?p=56022025-09-22T16:53:59Z2025-09-22T16:50:18Z
Imagine your car won’t start. Your mechanic has a theory: “The battery is dead.” Now, they have several ways to share that theory:
Imagine your car won’t start. Your mechanic has a theory: “The battery is dead.” Now, they have several ways to share that theory:
Option 1: Launch a podcast. They passionately argue their case, dismissing other theories as idiotic or from obviously corrupt people.
Option 2: Write an op-ed. They cite sources, quote esteemed mechanics, and wrap their theory in intellectual flair.
Option 3: Go on TV. Dressed to impress, they promise to reveal “the real truth” that others have hidden.
Option 4: Publish a book. Hundreds of pages on the philosophy of car repair, tracing its lineage to Carnap and the Vienna Circle.
Option 5: Test the theory. Do a voltage check. Swap out the battery. See if the car starts.
Only one of these options is accountable to the truth.
This is what scientists do every day. They test. They measure. They validate. So when scientists are lectured to by people who choose the first four options—performance over proof—it’s wildly uncompelling. If your way is better, show us. Prove it.
The first four paths can be lucrative. Their accountability is to audience engagement, not truth. Attention becomes currency. Books, subscriptions, ad revenue—they flow from emotional hooks: conspiracy, grievance, ridicule, outrage, or even the rush of a superficial insight from intellectutainment like a slick TED talk or a blowhard pop sci book. But these commentators aren’t accountable for solving problems. They’re accountable for keeping you watching.
Most of us work differently.
Mechanics, engineers, scientists, doctors, plumbers—we’re accountable to outcomes. To truth. To solving problems.
Postscript
Politicians are accountable to voters. But their appointees? They occupy a gray zone. Their job is to keep their boss happy—not necessarily to serve the public or solve problems. Whether they’re held accountable depends entirely on the elected official that appointed them. Their boss might just be another audience member, easily sated by their words, and unconcerned about their service or stewardship.