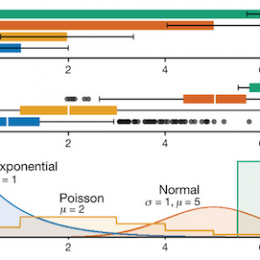
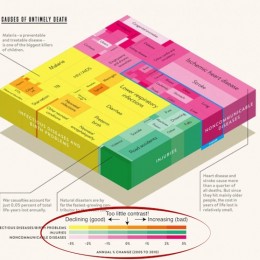
Protocols.io – 3 days left
Posted in Software
As Labrigger mentioned earlier this week, ZappyLab is running a Kickstarter campaign to jump start their crowd-sourced protocol repository, Protocols.io.
Perhaps the most attractive reward they’re offering for pledging are the Black Russian Espresso…