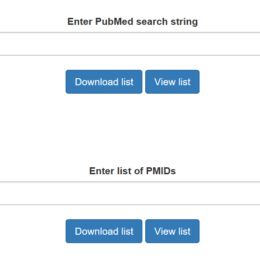
Finding out who cites your body of work
One of the most common ways that universities and institution use to evaluate scientists is to solicit letters of recommendation. But who should they ask? Of course former mentors will write letters. To get a…
One of the most common ways that universities and institution use to evaluate scientists is to solicit letters of recommendation. But who should they ask? Of course former mentors will write letters. To get a…
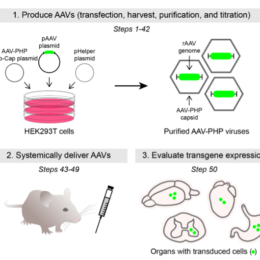
CRISPR/Cas9 technology has greatly accelerated the development of genetically engineered mice, but it’s still a big investment of time before the mice are ready. For quicker turnaround, there are other options (and speed isn’t…
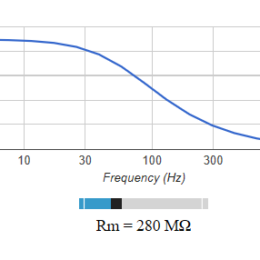
For teaching electrophysiology, there’s still a lack of comprehensive references. In particular, it can be difficult to impart to students an intuitive feel for the quality or fidelity of electrophysiological recordings. How close to the…

Daniel Fiole is curating a nice resource for 2p cross sections: twophotondyes.com
There’s a lot here. It’s not just dyes, he has links for fluorescent proteins as well, and there’s…

RayLab is an iOS app (iPhone/iPad) for optics analysis. It has some nice features– more than I expected. It’s a nice piece of work! For many practical applications it cannot replace conventional optic design software…
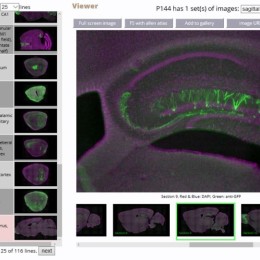
There’s a project in Sacha Nelson’s lab at Brandeis to generate and characterize enhancer trap mice for studying neural circuitry. They have a nice online searchable database of the lines they’ve generated,…

In the past, Labrigger has only rarely posted about relevant papers. That ends today. Now there’s a new post category for papers, and it’ll be used to highlight publications that are of potential interest to…

In the talk I gave at the Short Course at SfN 2014, I briefly discussed the process of optical system design. A common strategy is to start with a published design, or at…

When you run out of catalogs to read, Photonics has some nice short articles. It’s all pretty basic, not too complicated. Good for training (e.g., Optical design software, Fiber lasers)
…
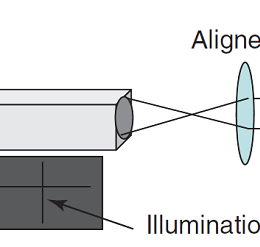
This is a nice, quick, and practical introduction to optical alignment. A good place to start for training. By Rainer Heintzmann.
…
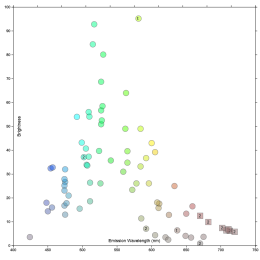
George McNamara recently posted a comment on spectra, which referenced this online app which is handy.
…
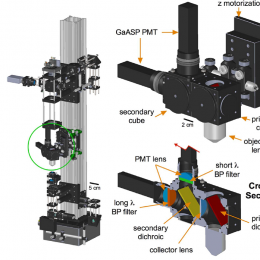
This open source two-photon microscope system is adaptable for both slice (with substage detection) and in vivo experiments, and is built with largely COTS parts. The paper is a very nice resource.
See also,…

Our friend Christian Wilms tipped us to Austin Blanco’s blog, which has some posts you all might be interested in:
Characterizing unknown optical components
A few notes on Arduinos, their timers, and using…

Kurt Thorn shared the parts list for his Abbe diffraction setup. He describes how to use it in his blog post, but you can also check out his talk.
…

How to measure the liquid junction potential
This is an old blog post, but the comments section is still somewhat active. Handy reference/training material.
…
{kind=link}
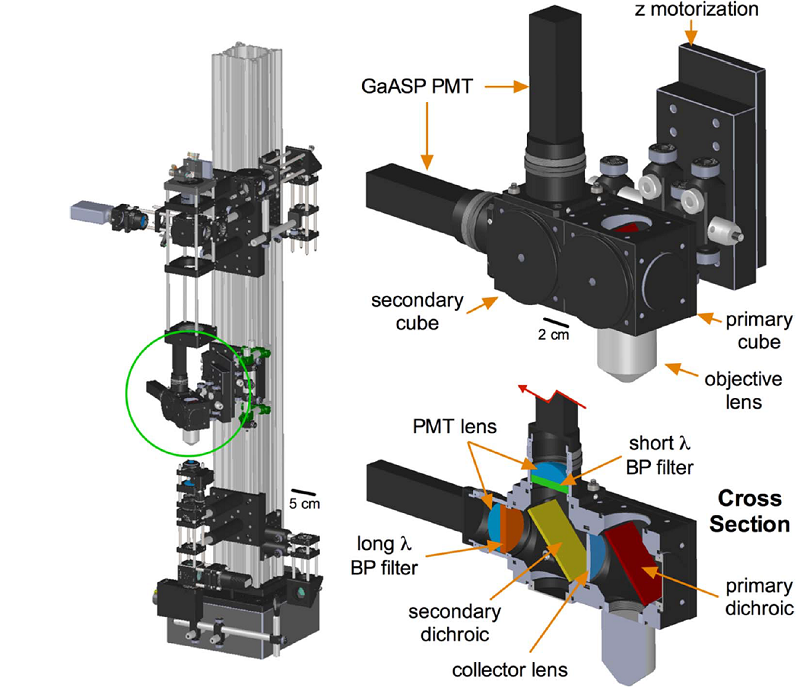{kind=link}
{kind=link}